
Subreddit Comment Classification with Naive Bayes
Introduction
In this blog post, I will walk you through how I have implemented a Naive Bayes classifier to classify whether a given comment belongs to a post in one of the three subreddits: Machine Learning, Data Science, and Artificial Intelligence. The dataset is provided here.
Also, be sure to stick around till the end for a quick video of me testing out the classifier on some Reddit comments randomly picked from the Internet to see how well it can perform!
Without further adieu, let's get started!
Naive Bayes and its application into the Classifier
On a previous post in which I presented how I built a Rotten Tomatoes Review Sentiment Classifier, I have briefly explained what Bayes Theorem is and how we can use it to "update" our believes given more evidence collected from reality. As a quick refresher, below is the Bayes formula again, with H as our hypothesis and E as the evidence observed.
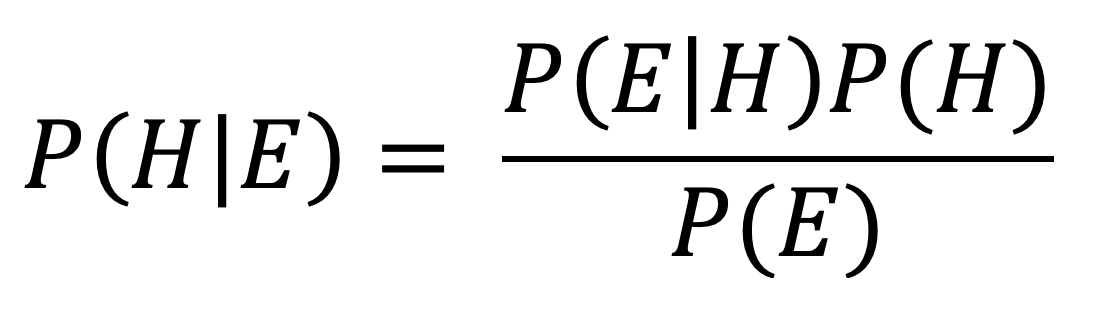
This time, I will elaborate a bit deeper on how all of the classification work is essentially based around this single formula.
In our current context, H will be either "MachineLearning", "datascience", or "artificial" (actual names of these subreddits); Thus, we have three priors P(MachineLearning), P(datascience), and P(artificial). On the other hand, the evidence E is the list of all words that a given comment will contain i.e. E = [w1, w2, w3, ... wn]. Integrating everything in the formula, we will have:

The three equations above basically share the same meaning, that is provided the subreddit prior and the probability a comment happens given it is in that subreddit, we can deduce the chance that this comment actually belongs to that subreddit class. As we assume Naive Bayes, the probability of a comment happening in a subreddit is just the product of all the likelihoods of its words to happen in that subreddit. Moreover, we can ignore the denominator, which is the probability of a comment, as it is similar for all three subreddit classes.
Once we have obtained all three chances of a comment to be in a subreddit class, the maximum one will decide that the comment is classified to be in the according subreddit.
Data Transformation
It would be easier to work with the data if it has the form of a column of comment text and a column of subreddit class. However, because these two pieces of data came in two separate files in the original dataset, I needed to merge them based on the post_id, as on line 10 in Figure 1. The result will be a desired dataframe having one column for comment text, and another for the subreddit class of that comment.
Moreover, as I discovered there existed some missing comment data, I executed line 12 in Figure 1 to remove the rows with missing comment text from the dataframe.
Comment Text Pre-processing
The comment text data needed to be processed first before it was ready for usage in training, validating, and testing the classifier.
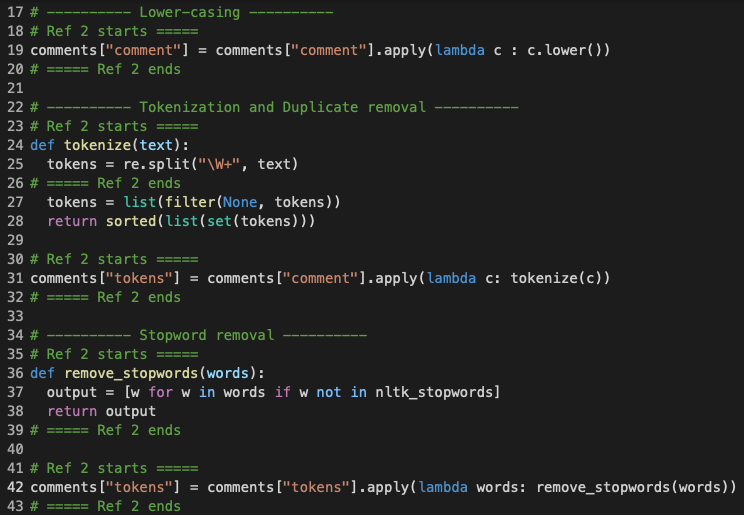
Firstly, by line 19 in Figure 2, all letters in comment text were lower-cased. For our classification purpose, there is no need to distinguish between the upper and lower cases of letters.
Secondly, from lines 24 to 31, comment text strings were tokenized. That is, comment strings were transformed into equivalent lists of only distinct word strings. For example, a string like "one one two three two" would become ["one", "two", "three"]. This tokenized format of comment strings were much easier for me to count the occurrences and then derive the likelihoods of different words given a subreddit class.
Next, from lines 36 to 42, all common stopwords given by the NLTK package were removed from the comment token lists. Stopwords are words considered to be neutral and irrelevant in terms of text classification, and such words can be articles, pronouns, possessive adjectives, etc. Here, I made use of the NLTK's pre-defined list of common stopwords in English.
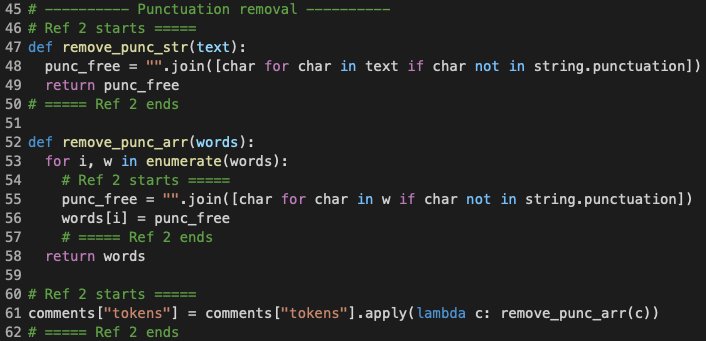
For now, I have obtained comments tokenized into lists of distinct word strings. However, these words might still contain unwanted punctuations, which were what I removed in this step.
I defined two separate functions, remove_punc_str and remove_punc_arr. The first is used on a comment that is still a whole text string, whereas the latter is used when the comment has already been tokenized into a list of word strings. In the case of my current implementation, I am using remove_punc_arr as I have already tokenized the comments previously. If it was not for stopword removal, I could have performed punctuation removal before tokenization; However, some NLTK stopwords still contained punctuations, thus I needed to remove punctuations after the comment had already been tokenized and got its stopwords removed.
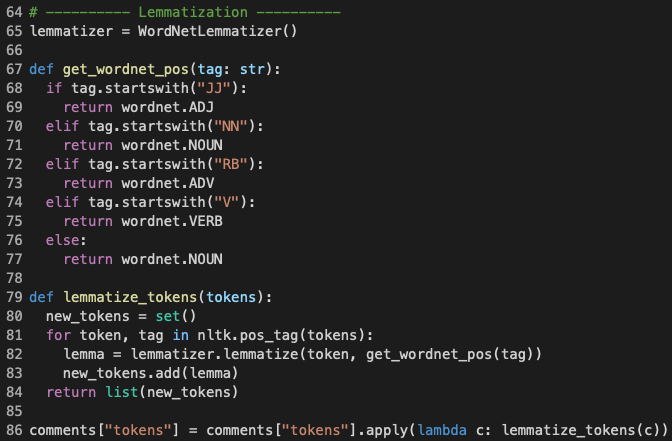
The final pre-processing step that I performed was to lemmatize the tokenized comments. Lemmatization transforms a word back to its base form given the context of the whole comment. For example, "programmed", "programming", and "programs" can be all converted to "program".
I made use of a pre-trained lemmatizer called WordNetLemmatizer, which is part of the NLTK package. For the lemmatizer to work best, I needed to provide which word types (noun, verb, adjective, and adverb) that I wanted the lemmatizer to try and convert the provided word to. Hence, this further meant that I must be able to recognize the type of a given word string, which was done by another pre-trained NLTK model and callable as the function pos_tag (line 81 in Figure 4). Once pos_tag had tagged a word with a word-type label, that label was then passed on to the get_wordnet_pos function to deduce the equivalent tags that would be fed into the lemmatizer.
After this step finished, what I got then were tokenized and lemmatized comments, which were ready to be used for classifier training and testing.
Randomly Split the Dataset
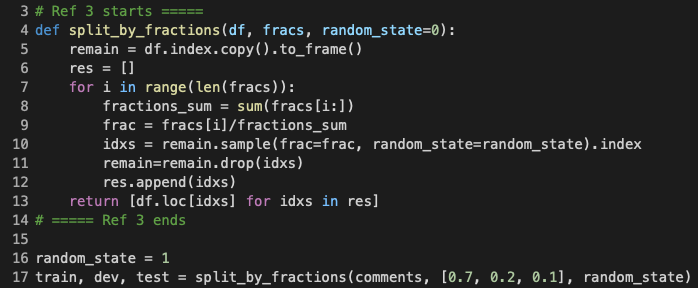
train, dev, and test sub-datasetsI randomly splitted the dataset into train, dev, and test sub-datasets using the function split_by_fractions, presented in Figure 5 above. The train set took up 70% of the data, dev took 20%, while train took the remaining 10%.
This method of dataset splitting was the same as the one I used for my Rotten Tomatoes Review Classifer, which I have experimented and proven that different random_state values should not affect the classification performance. Hence, as per my final implementation, I chose to stick to a fixed random_state value of 1.
Train the Classifier
Calculate the Subreddit Class Priors
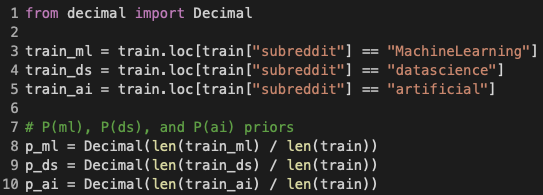
Priors, again, are the probabilities of the different hypotheses P(H). In our case, the hypotheses are the three subreddit classes "MachineLearning", "datascience", and "artificial", and their priors were set to the percentage each of which occupied in the train set, as seen on lines 8 - 10 in Figure 6 above.
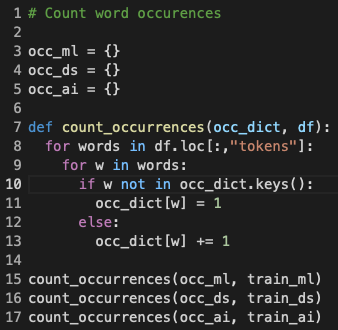
Next, I counted the occurrence of each word in the tokenized comments given that the word was in one of the three subreddit classes. The end result of this step was the three dictionaries occ_ml, occ_ds, and occ_ai, each of which contained the word strings as keys and their respective counts as values.
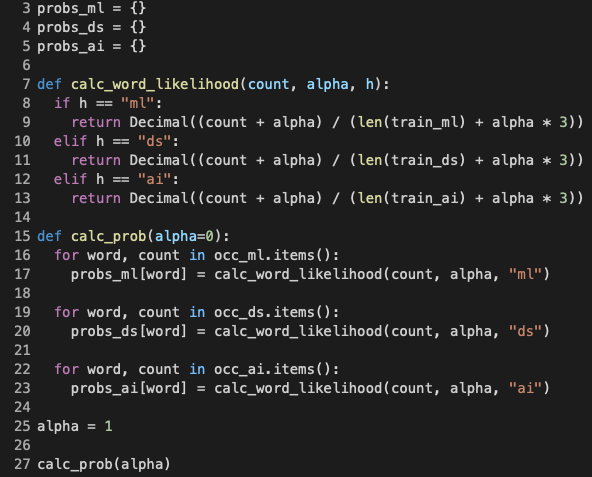
As the final step of training, I calculated all the likelihoods of the words given one of the three subreddits.
The function calc_word_likelihood (lines 7 - 13 in Figure 8) calculated the likelihood of a single word provided its occurrence count, smoothing parameter alpha, and the hypothesis h. Smoothing was applied to eliminate the Zero Probability problem, where a word encountered during validation or testing was never seen before during training, hence the classifier would definitely fail to decide the appropriate subreddit class. In the next section, I will discuss in more details how I have experimented with the smoothing hyper-parameter alpha to achieve the best classification performance.
The function calc_prob (lines 15 - 23) then in turn iterated over all the three occurrence dictionaries and called calc_word_likelihood to produce the likelihoods of all words given the three subreddits. This function received alpha as its parameter for smoothing tuning.
As a final result, we finished training by obtaining the three word likelihood dictionaries probs_ml, probs_ds, and probs_ai, all of which would be directly used in classification.
Cross Validation with dev and test Datasets

The function classify in Figure 9 above, provided the comment_words and smoothing parameter alpha, would classify which subreddit that comment belonged to.
Lines 7 - 12 are where I dealt with the Zero Probability issue. If a word was not found in the likelihood dictionaries, it would mean that the word had not been encountered during training, and hence its current occurrence/likelihood was 0, causing the whole chance product to become 0. This is when alpha came into play. For words with zero occurrence, alpha would be the decider of how many counts to pad in to eliminate those zeroes.
The remainder of the function calculated the three chances that comment_words would fall into or happen in those subreddits. The subreddit with max_chance would be the classification assigned for that comment.
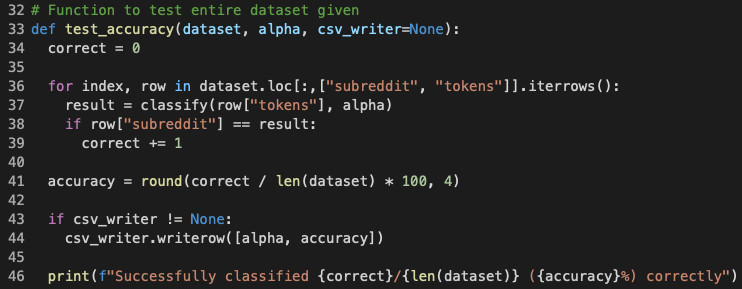
Finally, to test the classification accuracy on a whole dataframe, I created the function test_accuracy and passed to it the whole dataset and smoothing parameter alpha. The function would iterate over the whole given dataset, called classify on each of the comments with alpha, and add up the number of correctly classified comments. The accuracy was determined by the ratio of correctly identified over the total number of comments.
Smoothing Experiment
The smoothing experiment dealt with finding out the best smoothing parameter alpha that would result in the best classifier performance. And as I incremented the value of alpha from 0 to 10, the followings are what I have observed:
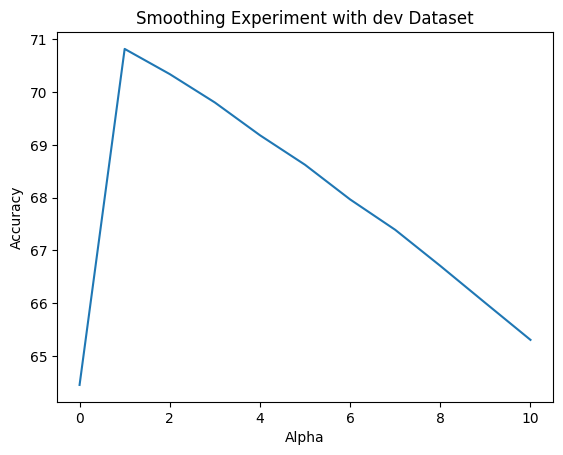
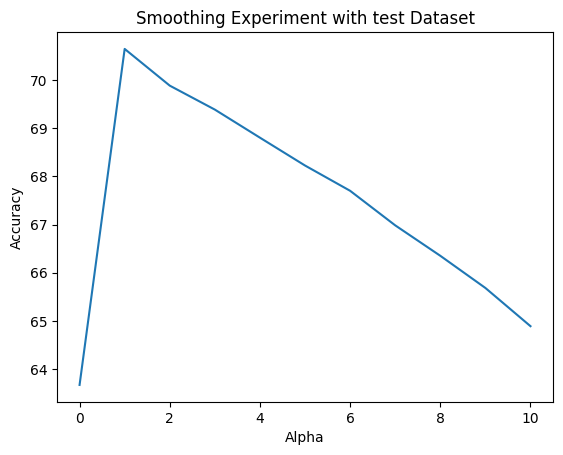
For both the dev and test sets, the performance behaviors were consistent as I altered alpha. The accuracies peaked at approximately 70% when alpha was set to 1, but then quickly decreased as alpha was incremented towards 10. To easier judge the consistency, we can take a look at the merged line graph below:
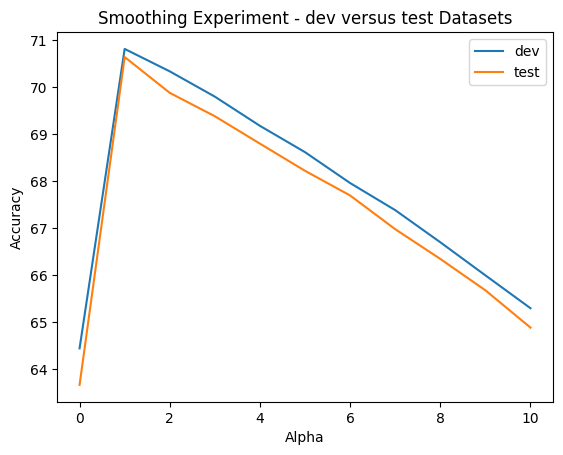
And, we can obviously see that test performance was just slightly off and below that of dev. But nonetheless, the consistency in performance between them reassures us that the classifer was not overfitting, and the best value for alpha would be 1.
Stopword Removal & Lemmatization Experiment
I was curious if applying stopword removal and lemmatization would significantly improve the performance of the classifier, and the followings are my findings:
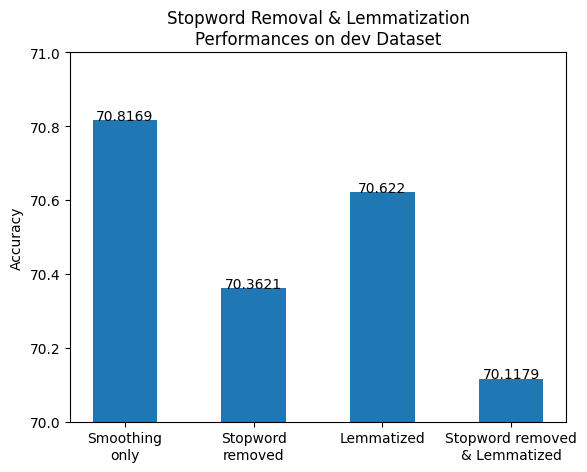
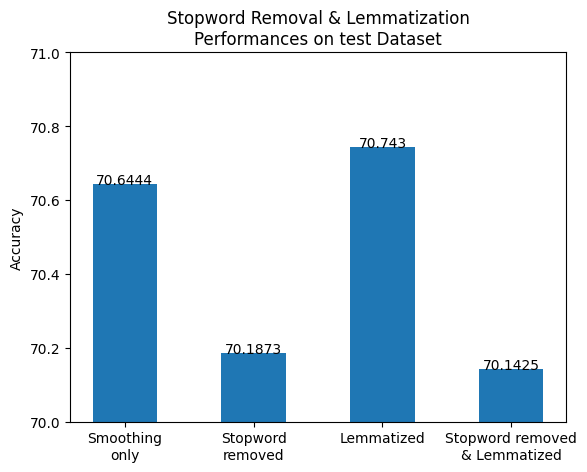
For validation with dev set (bar chart on left), whether it was stopword removal only, lemmatization only, or both applied simultaneously, the accuracies could not beat that of one-smoothing only. However, much to my surprise, in case of the test set (bar chart on right), the lemmatization-applied classifer did perform slightly better than the one with smoothing only. We can take a look at the combined version of the two bar charts for a better comparison here:
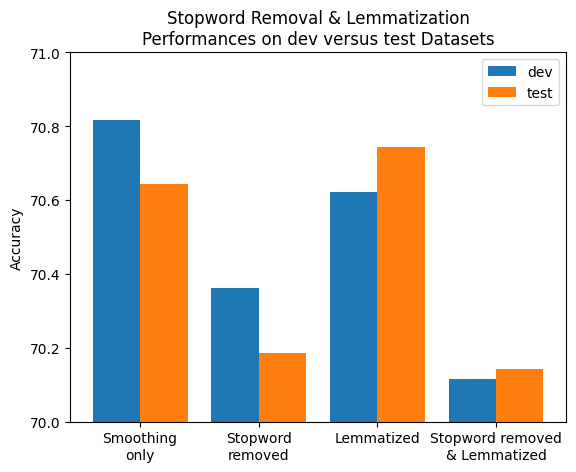
Although the drops and pumps in accuracy were trivial, the experiment did show that stopword removal and lemmatization could have a positive effect on performance of the classifier if done correctly and appropriately for each different kind of dataset. Moreover, we need to keep in mind that lemmatization takes a large amount of time to perform, thus if classification speed is crucial, we should carefully consider the usage of lemmatization.
Conclusion & Demo Video
The performance of the classifier at 70% accuracy can be considered acceptable. Nevertheless, there is still a lot of room for improvements.
The most potential improvements, in my opinion, to be performed in the future are to build a custom list of stopwords specifically for this dataset only, to more closely examine the effects of lemmatization as well as experimenting with other lemmatization techiques, and to provide more quality data, as currently the amount of "artificial" comments is much lesser than those of the other two subreddits.
The following is a demo I have performed using the classifier trained with smoothing of 1 and lemmatization, stopword removal was omitted:
P.S.: The full code implementation and references can be found here